


Disaster Recovery in Data Engineering: Best Practices to Safeguard Your Systems
Master disaster recovery in data engineering with best practices—protect pipelines and avoid downtime

Introduction
What happens when your data pipeline crashes at 3 a.m. and your backups are corrupted—or worse, missing? In data engineering, disaster recovery isn’t a luxury; it’s a must-have strategy. Businesses lose billions annually to downtime and data loss. Whether it’s a hardware failure, a bad SQL query, or a cyberattack, the stakes are high. This post dives into why disaster recovery matters and delivers actionable best practices to keep your systems resilient. By the end, you’ll have an idea of how to protect your data engineering workflows from chaos. Ready to fortify your pipelines? Let’s get started.
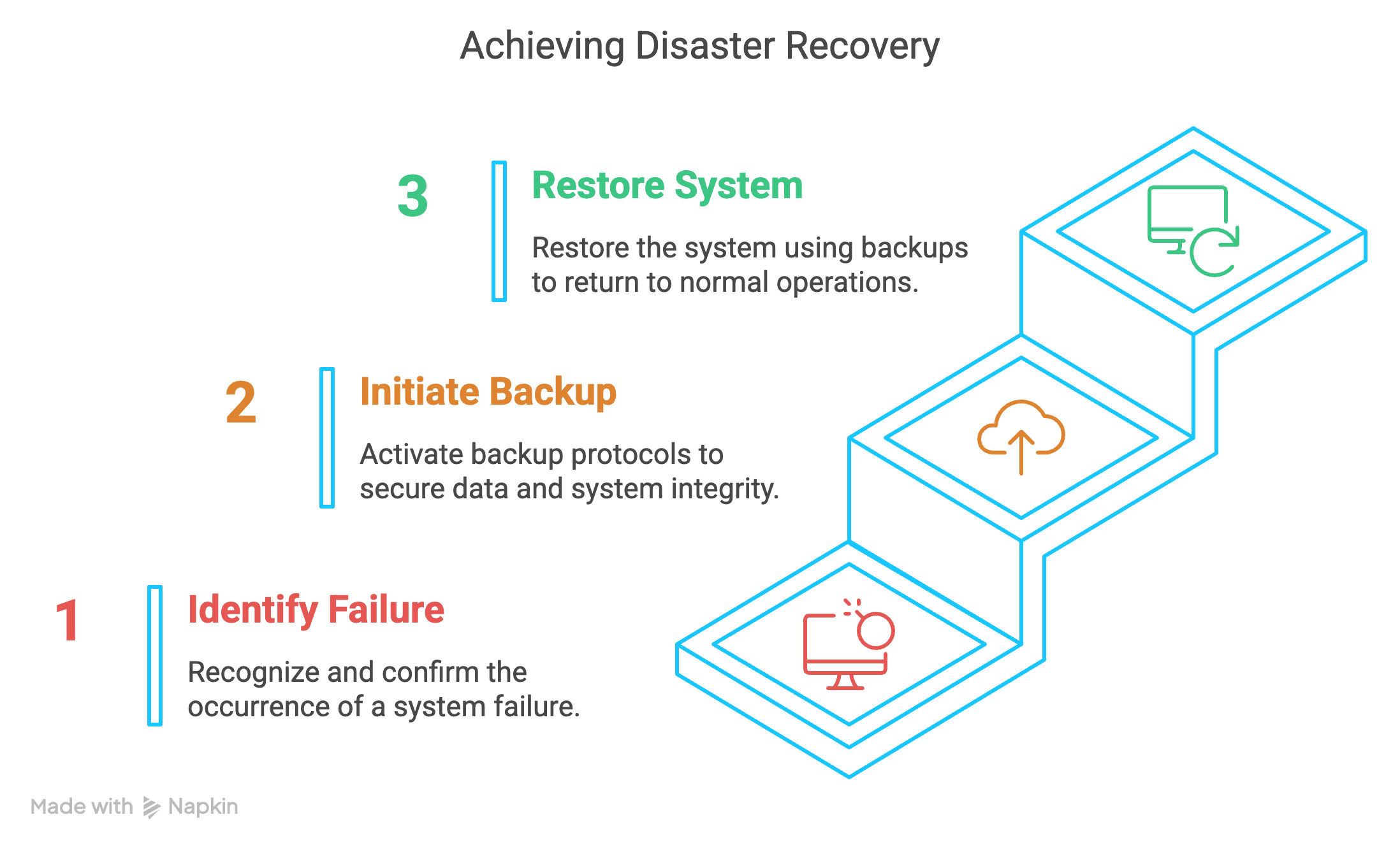
Why Disaster Recovery Matters in Data Engineering
Data engineering powers everything from analytics to AI, but it’s also a house of cards without a solid disaster recovery plan. A single point of failure—like an untested backup or an overloaded server—can result in hours of downtime or permanent data loss. If you add human errors (for example, accidental table drops) and natural disasters, the risks pile up fast.
The good news? Robust disaster recovery practices in place can reduce recovery times and save your team from panic mode. Let’s explore how to build that resilience below.
Core Principles of Disaster Recovery for Data Engineers
Plan Ahead with a DR Strategy
Every solid disaster recovery plan (DRP) starts with two metrics:
Recovery Time Objective (RTO)—how fast you need systems back online—and Recovery Point Objective (RPO)—how much data you can afford to lose.
A fintech firm might demand an RTO of seconds, while a batch-processing data warehouse might tolerate hours. Define these upfront, then document failover steps.
Automate Backups and Testing
Manual backups are problematic. Automate the backups on a regular basis with tools like Apache Airflow for scheduling or cloud-native options like AWS Backup. But don’t stop there—test this automation monthly and validate that it is working as expected. A backup you can’t recover is just expensive.
Embrace Redundancy
Redundancy is your safety net. Replicate data across regions (e.g., AWS Multi-Region setups) or use distributed systems like Apache Kafka for fault tolerance. Yes, it’s costly—but it's cheaper than rebuilding from scratch.
Pro Tip: Simulate a failure quarterly to spot gaps in your DRP (a fire drill for your data and pipeline jobs).
Best Practices for Data Engineering Resilience
Here’s your checklist for bulletproof data pipelines:
Use Version Control for Pipelines
Track every change with Git and pair it with data lineage tools. If a transformation goes wrong, you’ll know exactly what broke.Monitor Systems Relentlessly
Setting up real-time alerts, starting with a simple email trigger, is an easy way to start. Catch a failing ETL job before it snowballs into a disaster.Document Everything
From DRPs to table schemas, clear docs save time when the clock’s ticking and hitting SLAs/SLOs. Bonus: They onboard new engineers faster, reducing onboarding timeLeverage Cloud Solutions
Cloud platforms or Cloud Data warehouses offer built-in redundancy and recovery tools. Offload the heavy lifting and focus on your logic.
These habits turn chaos into a manageable thing.
Real-World Examples of Disaster Recovery Done Right
Take a hypothetical e-commerce giant, “ShopFast.” When a ransomware attack locked their primary database, their multi-region backups kicked in. Automated failover rerouted traffic to a standby cluster in under 10 minutes—thanks to a tested DRP and redundant cloud storage. Customers barely noticed. Compare that to a competitor who lost two days rebuilding from scratch. The difference? ShopFast planned, automated, and monitored.
Your takeaway: proactive disaster recovery isn’t just insurance—it’s a competitive edge.
Conclusion
Disaster recovery isn’t optional—it’s the backbone of modern data engineering. Plan with RTO and RPO in mind, automate backups, embrace redundancy, and monitor like your business depends on it (because it does). Start small: test one backup this week or document a critical pipeline. Your future self will thank you.
What’s your go-to DR tip? Drop it in the comments or subscribe for more data engineering deep dives. Let’s keep our systems unbreakable.